Desarrollamos distintas métricas (analíticos) a partir de tres modelos de procesamiento natural del lenguaje con redes neuronales que nos permitieran tazar similitudes, relaciones y aproximaciones a las preferencias electorales desde lo que se comenta y dice en Twitter-X.
Las métricas que desarrollamos son las siguientes:
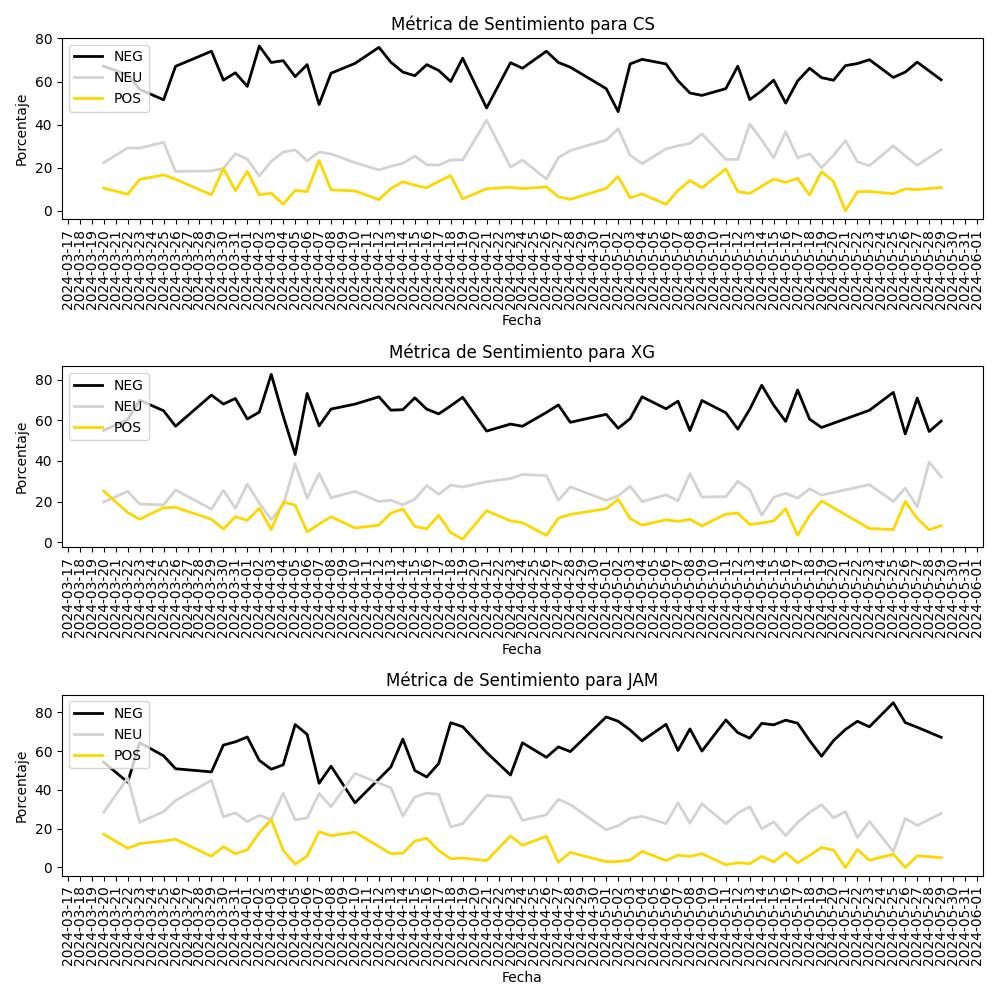
Clasificador de Sentimiento:
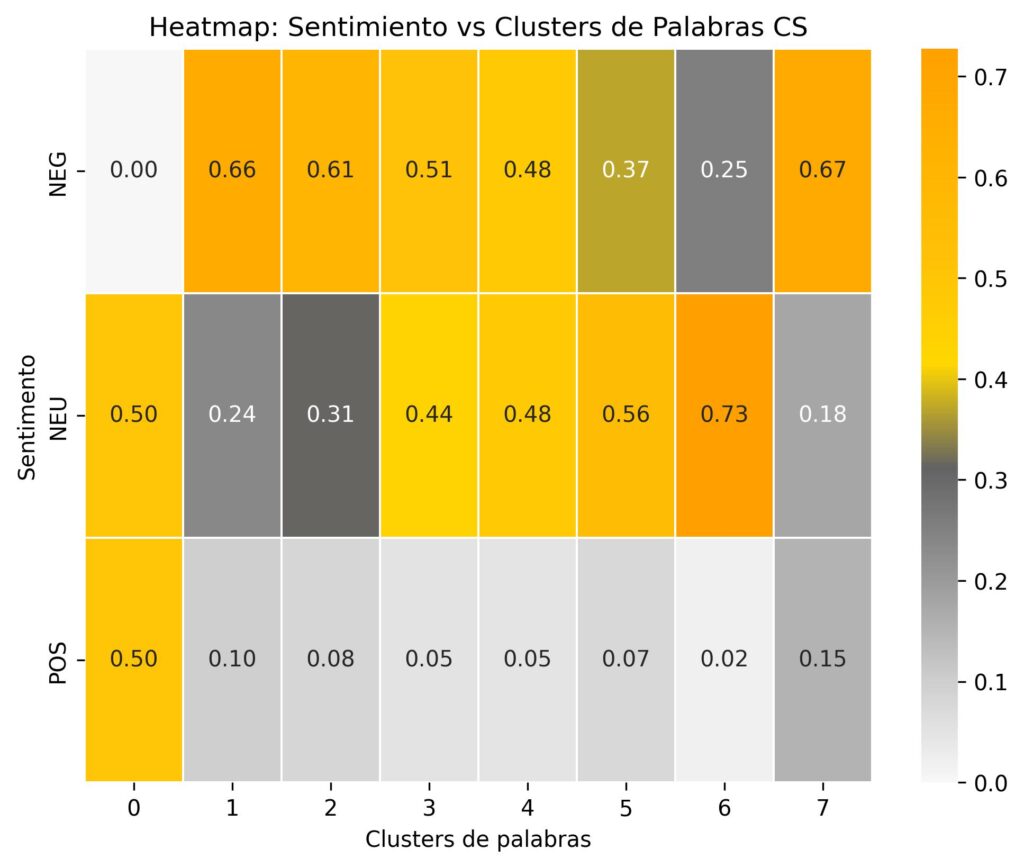
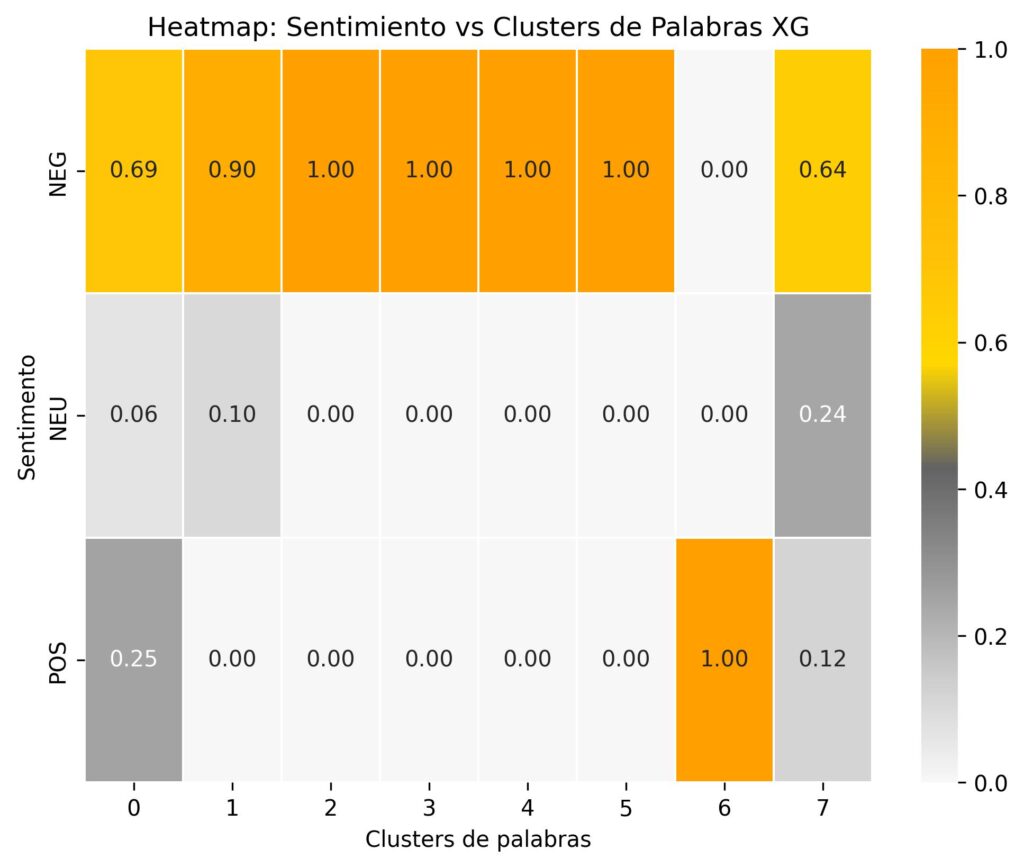
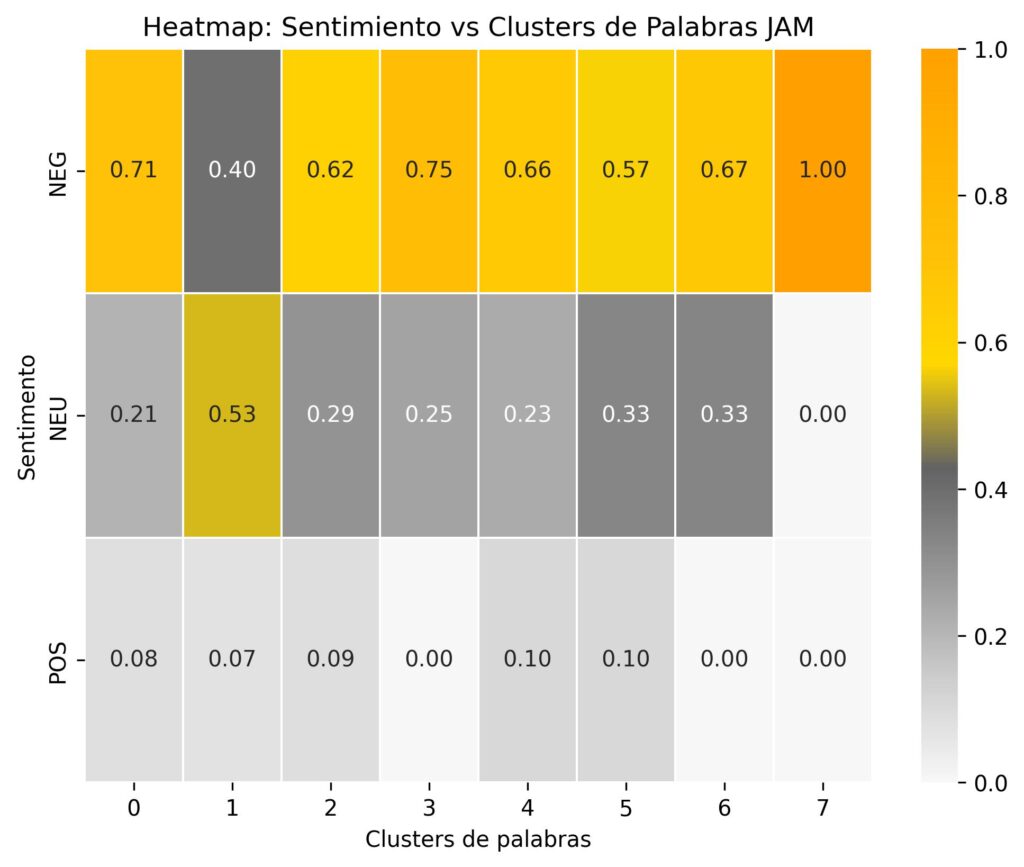
Predecir si un tuit es Positivo, Negativo o Neutro respecto de algún candidato
Clasificador de Movilización:
Predecir si un tuit significa participación y movilización a votar por algún candidato
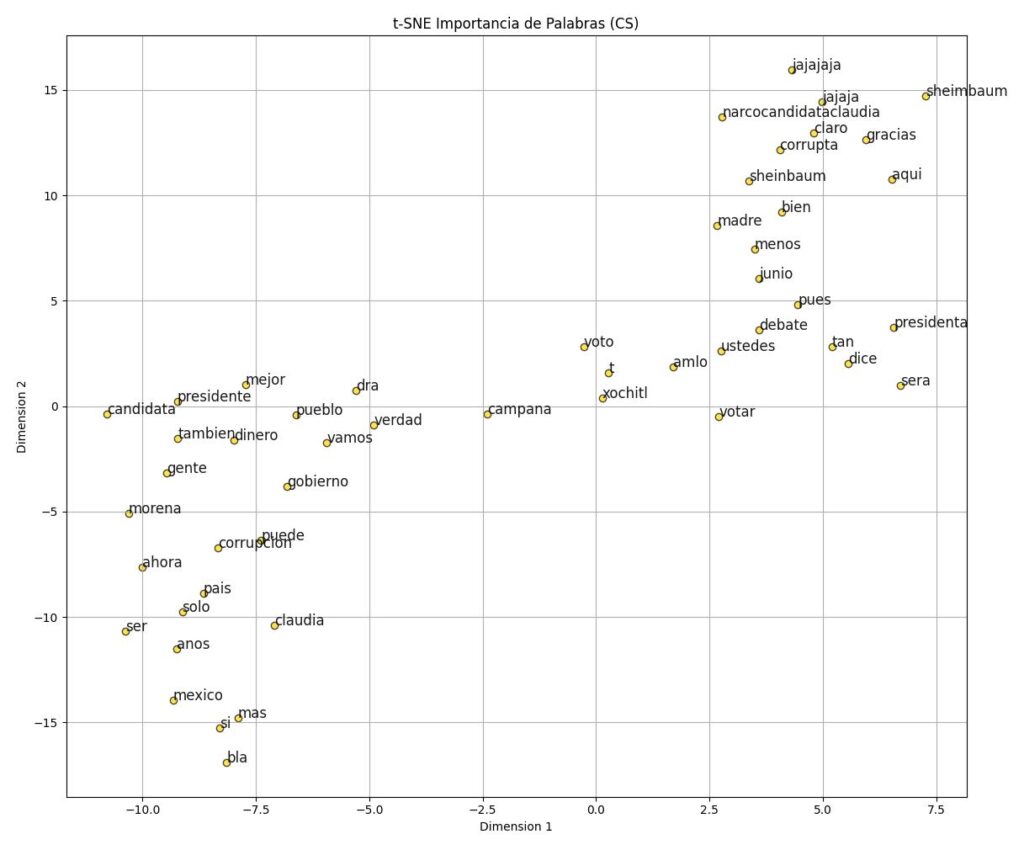
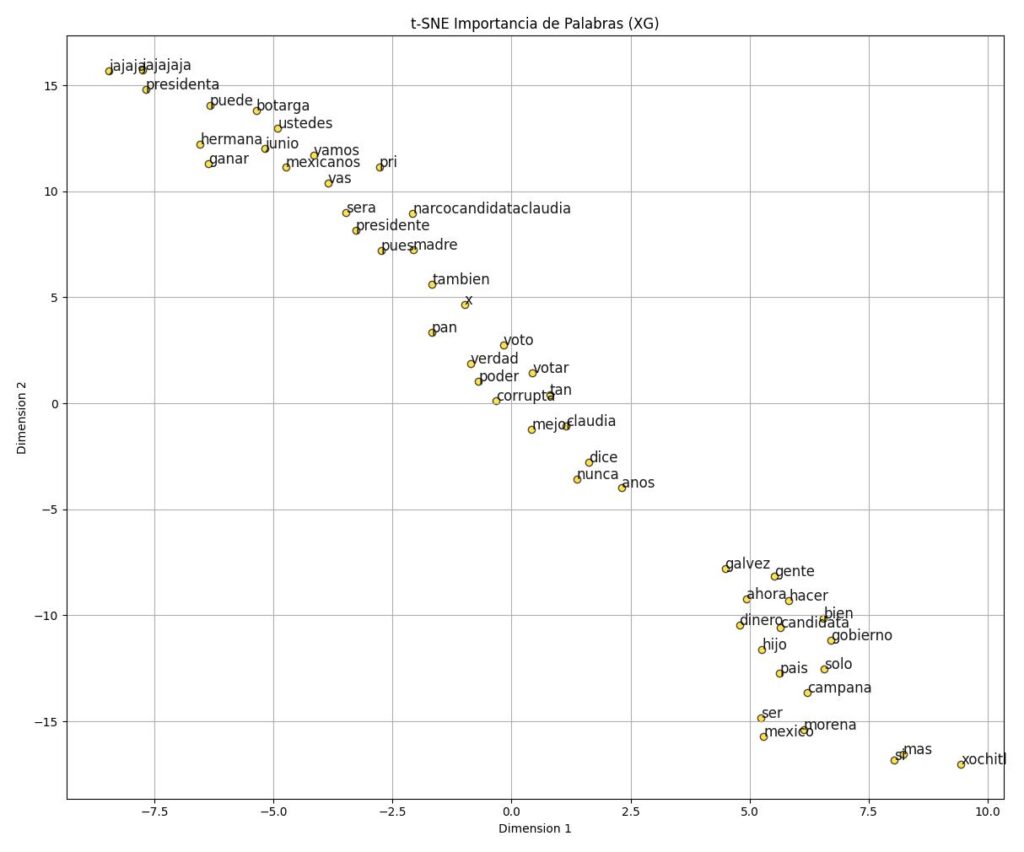
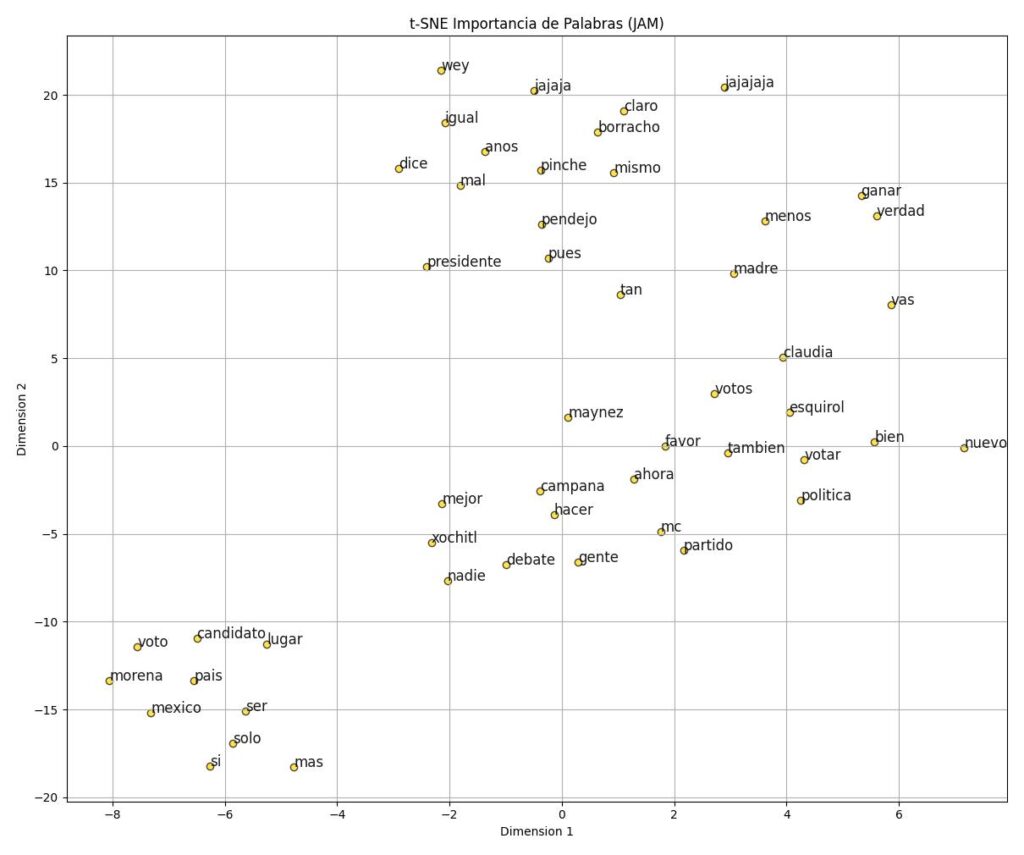
Segmentación
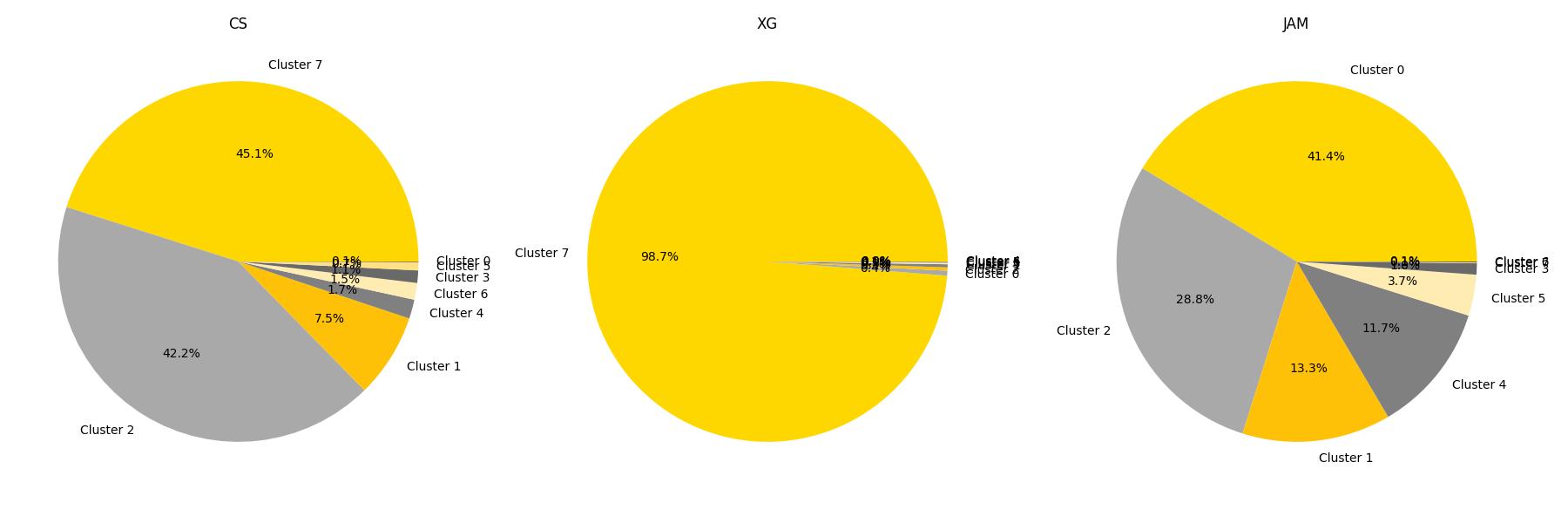
Agrupación de los distintos candidatos a partir de ciertos significados, palabras relaciones semántica y mensajes.
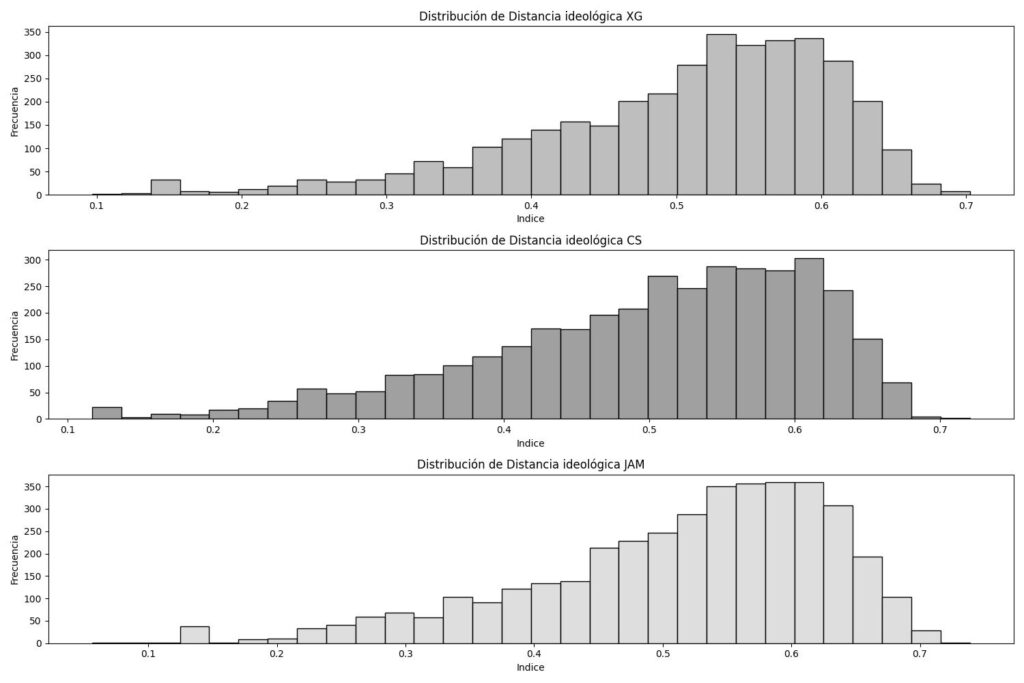
Afinidad Ideológica
La diferencia que existe entre lo que un candidato dice a partir de sus discursos y lo que se expresa en los tuits que los mencionan. A menor afinidad, menor es la cercanía entre textos, es decir, entre lo que dice el candidato y entre lo que dice el tuit. A mayor afinidad, mayor es la cercanía entre textos, es decir, entre lo que dice el candidato y entre lo que dice el tuit.
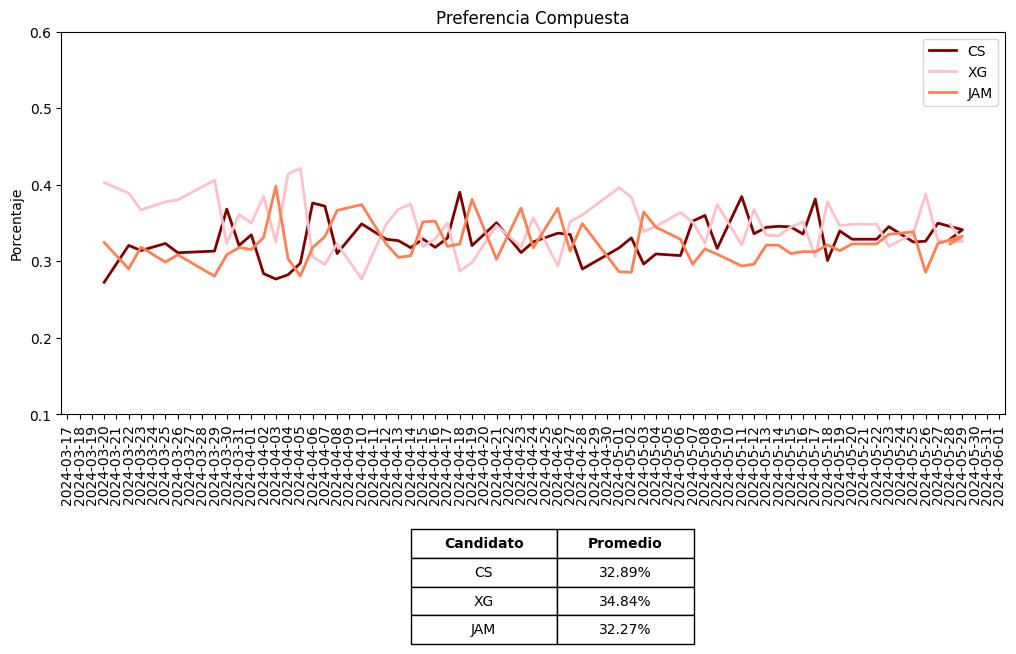
Preferencia
Una métrica compuesta que promedia las métricas de sentimiento, de participación o movilización y la distancia ideológica.
¿Cómo?
A partir de un Large Language Model (LLM) pre-entrenado de código abierto, de la plataforma HuggingFace (Robertuito)*, clasificamos de manera automática, 7349 tuits que tuvieran como criterio de selección alguna mención a cualquiera de los tres candidatos a la presidencia en: Positivo, Negativo y Neutro. Y de la misma manera, con otro algoritmo de código abierto llamado (Roberta)* clasificamos los textos como si invitan o no a la participación o a la movilización de alguno de los candidatos.
A demás, de manera manual, un equipo de tres personas clasificamos otros 3000 tuits que tuvieran como criterio de selección alguna mención a cualquiera de los tres candidatos a la presidencia en: Positivo, Negativo y Neutro.
Con la clasificación manual y con la automática hicimos una calibración del (LLM) para que la clasificación de textos fuera más prístina, clara y reflejara sentimientos, emociones, actitudes y valoraciones reales respecto de los candidatos a la presidencia y que estuviera adaptado a los localismos semánticos y sintácticos del mexicano.
Realizamos posteriormente, un proceso de limpieza adicional de los textos con criterios extras de clasificación como incluir ciertos hashtags como negativos y positivos, así como algunas palabras frecuentes con connotaciones positivas y negativas encontradas en la clasificación manual y de igual manera seleccionamos una serie de palabras adicionales que significaran apoyo, participación y movilización para alguno de los candidatos.
Para calcular la distancia ideológica empleamos una métrica llamada (Cosine Similarity) que nos dice, qué tan diferentes son dos textos. Y con ello, tener una métrica de diferencia entre lo que dicen los candidatos y lo que dicen los tuits.
¿Qué es un LLM?
Es un tipo de inteligencia artificial, que utiliza redes neuronales para entender y generar el lenguaje humano de manera coherente y útil.
Se entrena utilizando grandes cantidades de texto para aprender los patrones de lenguaje, gramática y conocimiento general.
Estos modelos son utilizados para responder preguntas, clasificar textos, traducir idiomas, resumir textos, etc.
El LLM que utilizamos de pre-entrenamiento para desarrollar nuestras métricas fue entrenado con 500 millones de tuits.*
La lógica detrás de estos modelos (arquitectura) es que pueden predecir con base en una serie de probabilidades las palabras que siguen en una oración, así como entender sus posibles correlaciones y contextos.
Representatividad
Una de las principales cosas que debemos de tener en consideración es que la representatividad del universo que estamos retratando y analizando es acotada. La principal razón de ello es porque las unidades de medición no son individuos sino cuentas únicas de Twitter-X.
Estas unidades de medición no son representativas geográficamente ni sociodemográficamente de la población de México, sin embargo, consideramos que sí son representativas del universo de cuentas única que hay en Twitter-X México (17.5 millones) *
Así, el universo muestral que buscamos representar es el siguiente:
Muestra: 300 tuits diarios a partir del 18 de Marzo hasta el 2 de Junio.
Aleatoriedad: Descargas a distintas horas del día, bajo el criterio de que sean cuentas únicas minimizando la incidencia de Bots y excluyendo RT.
Fuentes
*https://arxiv.org/abs/2111.09453
*https://huggingface.co/pysentimiento/robertuito-sentiment-analysis
*https://huggingface.co/bertin-project/bertin-roberta-base-spanish
*https://github.com/pysentimiento/robertuito
*https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/